Streaming with Kafka
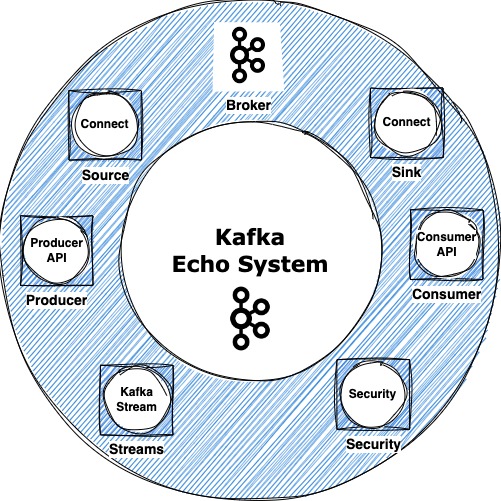
Kafka Echo System
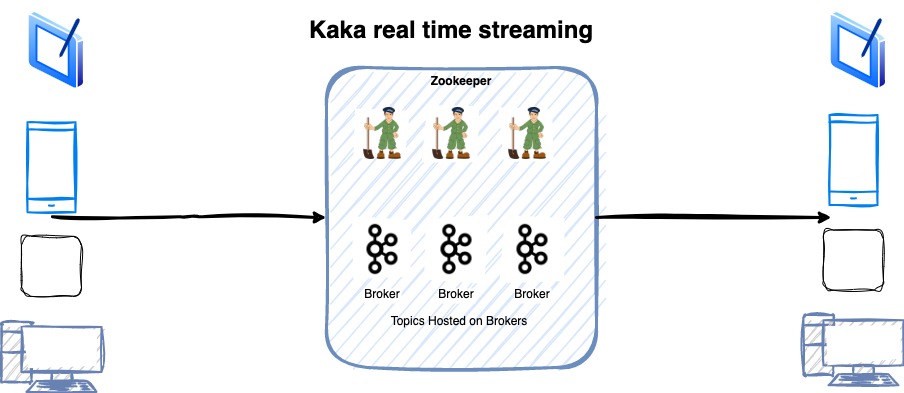
Kafka is combination of Kafka Broker and Zookeeper nodes. Zookeeper manages and broker nodes keep the data. In latest versions Zookeeper is removed with KRaft Kafka Protocol. You can say Kafka in latest versions will manage all its metadata by itself so there will be no dependency.
Besides main Kafka, Kafka is complete echo system, which contains many components. Each have its own importance. These components can improve productivity of your applications at scale.
- Kafka Producer and Consumer API’s
- Kafka Connect (Source and Sink Connect)
- Kafka Streams
- Security
- There are other products as well
Kafka Producer and Consumer
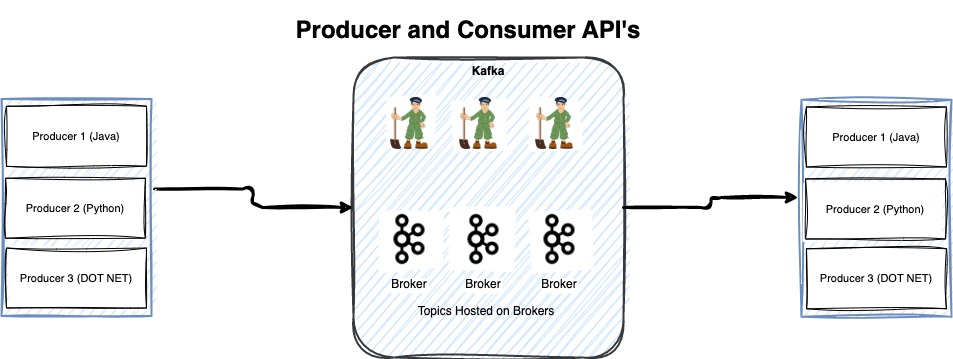
Kafka Producer and Consumer API’s are base of Kafka. This is quickest and fastest way to integrate your application and code with Kafka. Producer is to send events in Kafka and consumer is to read events from Kafka. Producer and consumer API’s need to be used in your own code to send events. Kafka Producer and consumer APIs are in many languages including Java, Python and .NET. High level diagram is below to explain how you can use these API’s. Note when you use producer and consumer API’s you need to maintain and develop all code base use cases. Moreover, if you use code-based option you also need to maintain all nonfunctional requirements. For example, you need to handle error handling and logging.
Important point of using producer and consumer is that if your application stops working at some point, it will resume from the same location where it stopped because of any error or network outage. The reason is that producer and consumer latest commits are saved in Apache Kafka topics. These topics are not for you. Kafka manages these configuration topics by itself.
Kafka Connect
Kafka Connect is very important part of Kafka echo system. Most of the time Kafka Connect is ignored, however we will shed some light on this important tool in Kafka echo system.
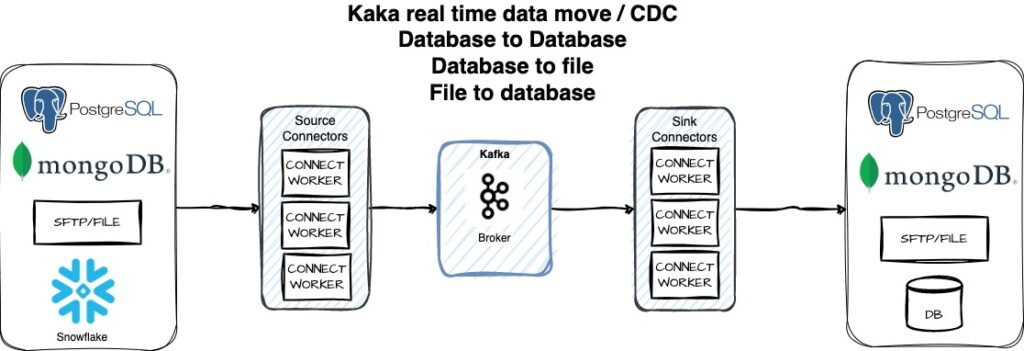
Kafka Connect integrates Kafka with many databases and other important market vendor products with very small or minimal effort. This is predeveloped system of integrations with very less coding and maintenance. Moreover, many non-functional requirements are handled in Kafka
Connect. for example, connection pooling, scaling, fail-over and not but lease is maintenance.
Kafka Connect work as a cluster and standalone mode. This is separate cluster than Actual Kafka Brockers (which handle Kafka data). Kafka Connect in standalone mode is only used locally on your laptop for testing your Kafka connectors. In any other environment this is recommended to run three node Kafka Connect Cluster.
Kafka Connect machine which also referred many times as Worker Node will run many Kafka Connectors. Kafka Connector connect with many databases and send and receive events from Kafka.
Types of Kafka Connectors
There are two types of Connectors, Source and Sink Connectors. These are used to send data to Kafka and read data from Kafka. For example, Kafka JDBC Source connector send events/data from JDBC Database to Kafka and Kafka JDBC Sink Connector read events/data from Kafka to JDBC Database. There are many different types of Kafka Connectors for example, Postgres Database Connector, AWS S3 Connector, JDBC Connector and many more.
Apache, Apache Kafka, Apache Zookeeper, Apache Kafka Connect & Streams and Apache projects logos and Apache open-source projects are trademarks of the Apache Software Foundation and Apache Flink®. All other software’s and logos are trademarks of their respective companies.